Blogs > AEM Sites : Indexing in AEM
AEM Sites
AEM Sites : Indexing in AEM
November 24, 2023Happy to find you all well. Let us discuss in today's blog an efficient way to perform search operations in AEM.
Indexing is a technique which enables the user to retrieve data with minimal node traversal and in minimum amount of time. Suppose, an AEM user wants to find all the images present in crx/de console which actually is categorized as a slow query in AEM as the process search gets terminated due to 100000+ node traversal. This is a case where you need to perform indexing upon desired property to retrieve the data (i.e images). Also in case where you need to enhance the search performance, it is recommended to perform indexing so that the data retrieval is cost efficient. Oak query engine supports XPath, SQL-2 and JQOM and Apache Oak-based backend allows multiple indexes to be plugged in a repository. PropertyIndex is predefined in repository itself, Apache Lucene and Apache Solr can be customized.
While executing a query
Case 1: No index is applied
Traversal Index is by default used to run the search.
Case 2:Multiple indexes as applicable for a search
Oak internally finds out the most cost efficient index and implements it for the search.
Diagrammatic Representation of Handling Indexes
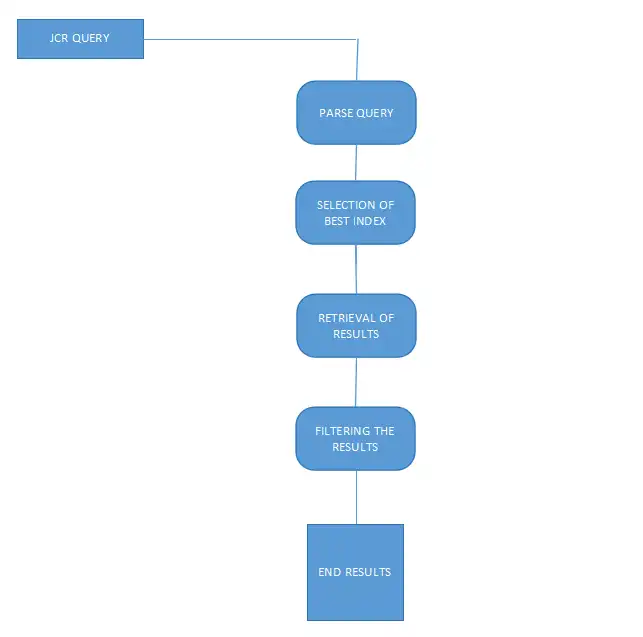
Creating Indexes in AEM
Oak supports Lucene indexing for property search (where an index is applied directly upon a property) as well as full text search. Here we will be focusing upon creating lucene indexings.
Steps for creating indexes in AEM
Under oak:index, in crx/de create indexing-in-aem as QueryIndexDefinition and add a mandatory property type lucene as shown in the xml. Also add the provided properties and rename the prop0 node as properties and you may also rename nt:base to nt:unstructured.

After successfully creating the index, you can find the generated index here
You need to find all the info as well as its consistency in

Also your index will be available in quickstart itself \crx-quickstart\repository\index If you are able to find the generated index in both the locations then congrats! You have successfully created your first index.
Lucene Indexing Example
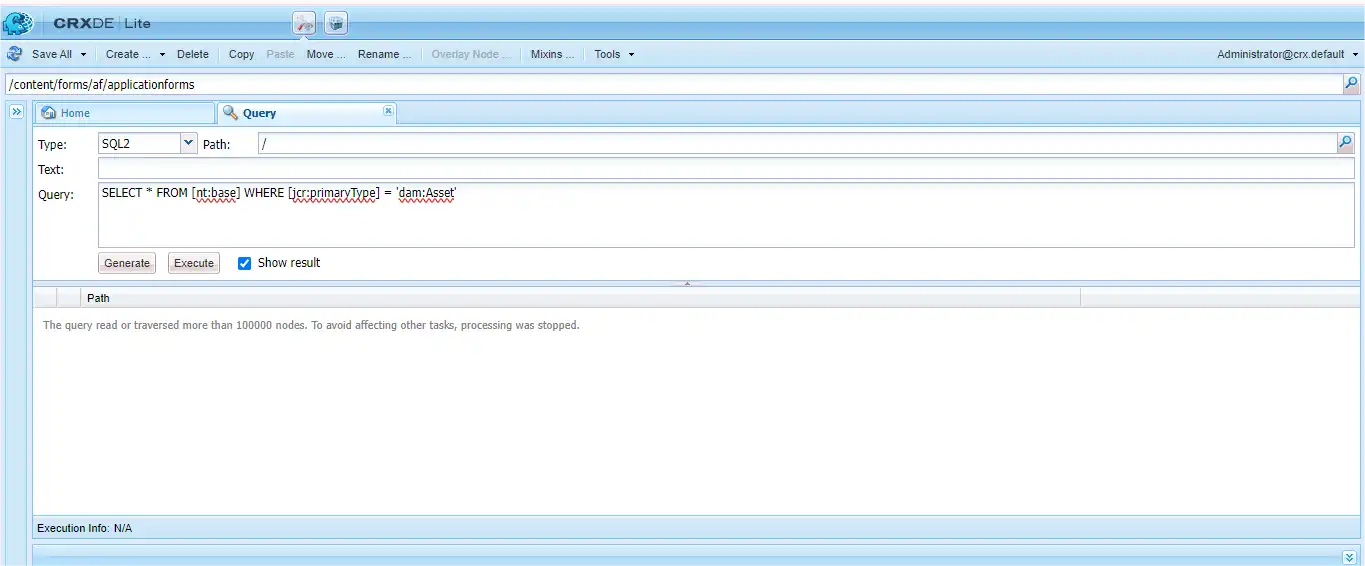
Oak engine for both property search as well as for full text search internally implements lucene indexing. Let us understand by an example. We need to search all the nodes in crx/de with property property dam:Asset from nt:base. Then for this we need to navigate to crx/de console, click on tools, the Query and select SQL-2 rather than XPath, enter the query for the search i.e
SELECT * FROM [nt:base] WHERE [jcr:primaryType] = 'dam:Asset'
, to find the node traversal reaches its provided limit and so the process search terminates.
Also while checking the query explanation from operation console, an error message gets displayed
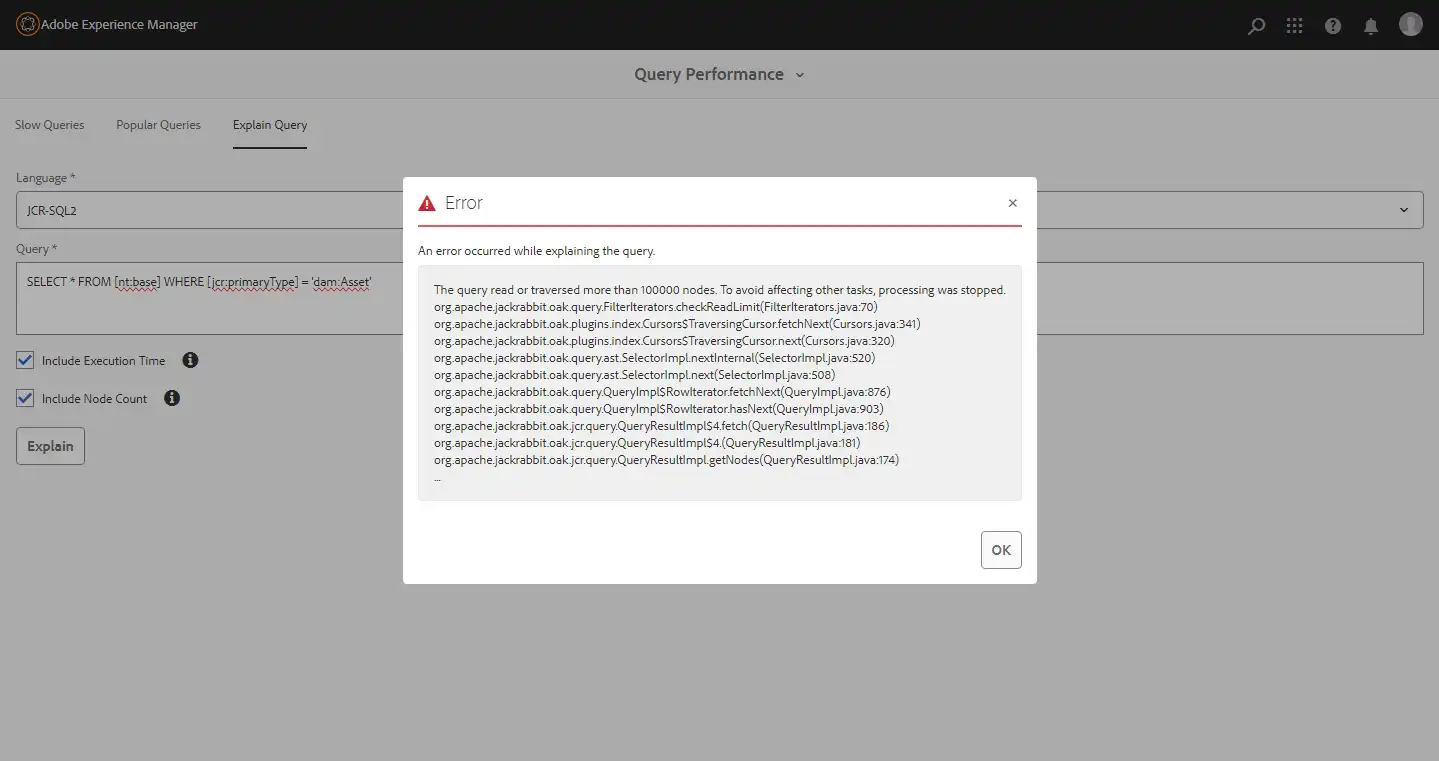
This triggers the need of creating an index over the property jcr:primaryType with sole reason to minimize the nodes traversed for the search to execute and generate the desired result.
In order to generate an index create assetType index (a node under /oak:index of type oak:QueryIndexDefinition) with provided properties.

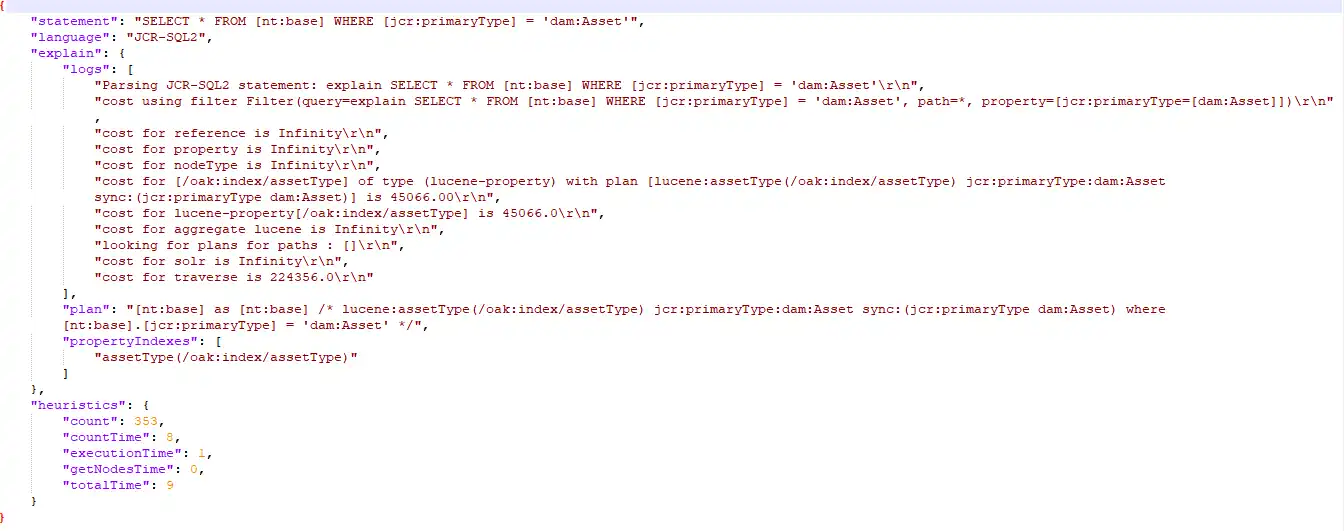
Re run the same query to get the results. You can also find you index applied on the search when you find the explanation of your query.
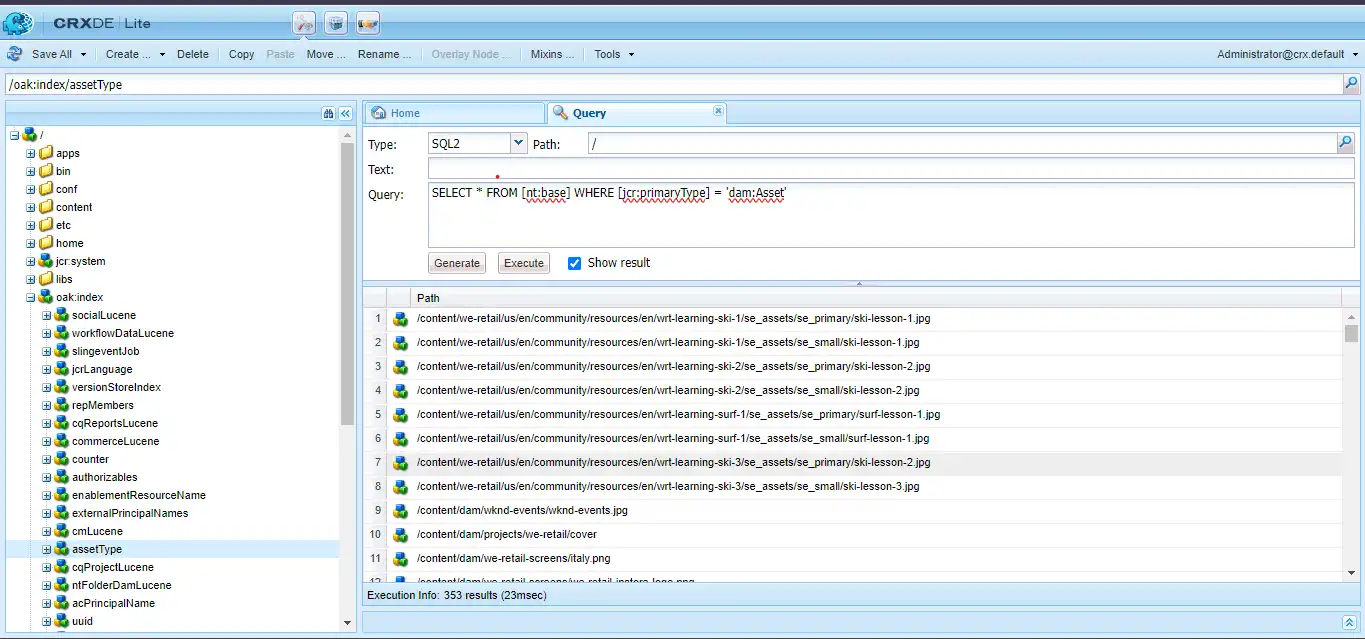
Here at the top you can find the assetType index applied for the generated search after clicking on Explain button.
Lucene Indexing Properties and Explanations
While performing lucene indexing, we have a variety of properties and nodes.
1.Node with type oak:QueryIndexDefinition
It has to have a mandatory property “type” “String” “lucene” else the node itself don’t save.
“compatVersion” “Long” “2” version 1 is deprecated and does not support property restrictions and index time aggregation whereas version 2 is faster to run queries.
“evaluatePathRestrictions” “boolean” “true” set the run to consider path restrictions provided.
“excludedPaths” “String[]” consists of paths which need to be excluded from search run.
“includedPaths” “String[]” consists of paths included for the search.
“async” “String” “async” it allows the index to keep running in the background even it multiple tasks are executing at a time.
2.Node name indexRules
They consist of configuration of index for provided node or property.
They consist of configuration of index for provided node or property.
Within this each first level node thus created will encounter the provided differed set of rules.
3.nt:base
It consists of property definitions in the form of node created under it as a property.
There can be variety of property nodes on which the indexing needs to be done.
The name of the prop0 needs to be converted to the name of the property itself to be indexed also the name property must be changed to the indexed property name.
“isRegexp” ”boolean” “false”, if set to true, then it will be considered as a regular expression.
“ordered” “boolean” “true” so as to implement order by clause.
“propertyIndex” “boolean” “true” allows to check equality condition, not null condition and ordering condition.
“sync” “boolean” “true” requires propertyIndex condition to be true always and ensures that the changes to the content are available as soon as they are committed.
4.Full text search in lucene indexing
And these indexes consist of entries of columns that contain the generated tokens. These inverted indexes fall handy while running the generated search.
Conclusion
Lucene indexing is hence a powerful mechanism that ensures fast retrieval of data. In case the requirement demands a customized property for the lucene search to execute, the property can also be generated in the backend.
The AEM crx/de itself has many ootb indexes which indeed avoids the traversal index search but in special cases, where node traversals exceed the declared limits, oak search engine applies lucene indexes for property, node as well as full text searches.
Hope you find this blog informative.


