Blogs > Query Builder in AEM
AEM Sites
Query Builder in AEM
| May 23, 2023If we talk about the Search APIs available in AEM, we have two options available with us i.e., Query Builder and JCR SQL2. We'll look into the query builder concept in this blog and get all the questions related to this topic cleared. So, let's get started.
Query Builder
In Adobe Experience Manager (AEM), a Query Builder is a powerful and flexible tool that allows us to create and execute queries to retrieve content from the AEM repository. It provides a structured and efficient way to search for specific content based on various criteria.
The Query Builder uses SQL-like syntax, but it's specifically designed for querying the AEM repository. We can build queries using a web-based interface or by constructing queries programmatically using the QueryBuilder API. It basically simplifies the process of searching for content and enables users to define complex queries with conditions and filters.
For example, we could ask the Query Builder to find all pages of a certain type in a specific part of our website. It's a handy tool for quickly locating and working with the content we're interested in within AEM.
We have a Query Builder Debugger Tool which can be used to execute the search queries on the JCR (Java Content Repository). We can use this tool for dry run purposes for our AEM queries.
AEM Query Builder debugger URL:
http://localhost:4502/libs/cq/search/content/querydebug.html
In the Query builder console, run a simple query like:
type = cq:Page
This query will provide us all the nodes having their primary type as cq:Page and we will get the search results in the form of hits.
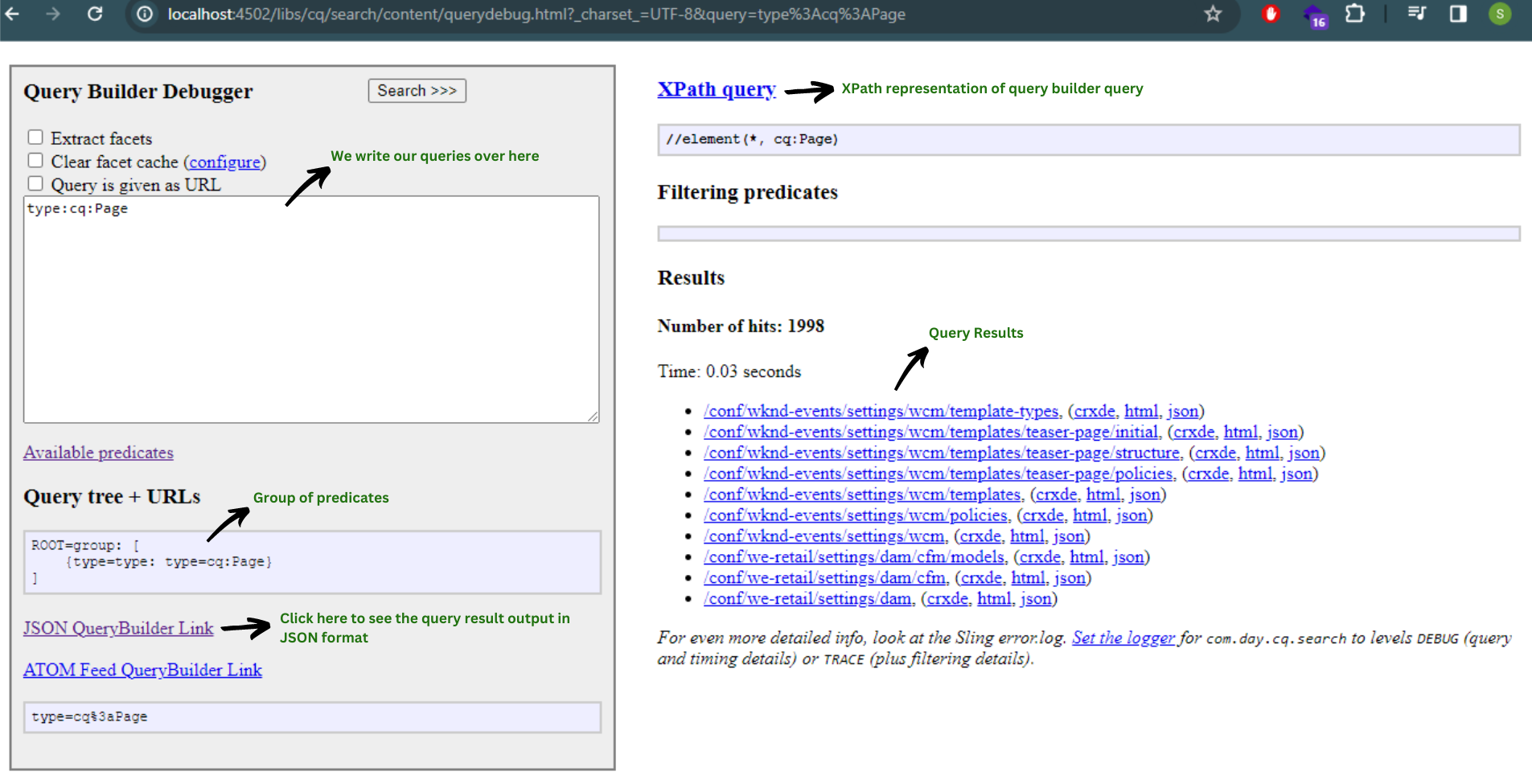
Query builder comprises of queries, so let's just look into what all a query consists of:
Predicates - If we don't provide any parameter, the predicate type is mirrored in the final query.
Parameters - Predicate parameter
Value - Value of predicate

List of Standard predicates
Here's the list of available standard predicates that we'll be using to write our query.
type : It is used for searching a particular type of node only. For ex. cq:Page, dam:Asset, nt:unstructured, etc.
-
path : It defines a particular path or hierarchy that needs to be searched.
path.self = true : If true, it searches the sub nodes including the main node given in the path and if false, it searches the sub nodes only.
path.exact = true : If it is true, the exact path is matched, if false all the descendants are included.
path.flat = true : If true, then it searches the direct children only.
-
property : This is used for search based on JCR property.
property.value : It defines the property value to be searched. Multiple values of the particular property could be given using n_property.value = xyz.
property.depth : It is used to specify the number of levels to search beneath a node. For example, when property.depth is set to 3, the search extends up to 3 levels below the base node. This parameter is mostly used for nested search.
property.and : In the case of multiple properties, the default behavior involves applying an OR operator. To switch to an AND operator set property.and = true.
-
property.operation : equals, unequals, like, not, exists.
“equals” for exact match (default)
“unequals” for unequality comparison
“like” for using the jcr:like xpath function
“not” for no match, (value param will be ignored)
“exists” for existence matches. (value can be true – property must exist).
-
fulltext : used for full text search
fulltext.relPath : can specify the relative path to search in (eg. property or subnode)
-
daterange : This predicate facilitates searching within a date property range.
daterange.property : Specify the date property on which query needs to run.
daterange.lowerBound : Fix a lower bound date range eg. 2020-08-31
daterange.lowerOperation : “>” (default) or “>=”
daterange.upperBound : Fix a upper bound date range eg. 2023-01-25
daterange.upperOperation : “<” (default) or “<=”
-
relativedaterange : It is an extension of daterange which uses relative offsets to server time. It also supports 1s 2m 3h 4d 5w 6M 7y.
relativedaterange.lowerBound : Lower bound offset, default=0
relativedaterange.upperBound : Upper bound offset.
nodename : This is used to search exact node names within the result set. It allows certain wildcards, such as nodename = text*, which searches for "text" and any characters following it. Similarly, nodename = text? looks for all records starting with "text" but excludes results containing only "text."
-
tagid : This predicate is used to search for a specific tag on a page by specifying its exact tagid. (Note:- It searches for tags within /etc/tags, so the service user used for the query must have access to this path as well.)
tagid.property : this can be used to specify the path of node where tags are stored.
tagsearch : It searches for matching tag.
mainasset : mainasset=true means search only Dam Asset and not the subassets.
group : This predicate is used to create logical conditions in your query. You can create complex conditions using OR & AND operators in different groups.
-
orderBy : This predicate is used to sort the result sets obtained in the query. e.g. orderby=@jcr:score or orderby=@jcr:content/cq:lastModified
orderby.sort : You may define the sorting way for the search results e.g. orderby.desc=true or orderby.sort = desc for descending and orderby.asc=true or orderby.sort=asc for ascending.
orderby.case : support case insensitive orderby.case=ignore (since 6.2)
orderby=my predicate (eg: orderby=path) : this can also be used to sort by path.
p.hits=full : Use this when you want to return all the properties in a node.
p.hits=selective : Use this if you want to return selective properties in search results. Use this with p.properties=sling:resourceType jcr:primaryType Example :- p.properties = jcr:path
p.nodedepth : Use this when you need properties of a node and its child nodes in the same search result. Use this with p.hits=full
p.facets=true : This will be used to Search Facets based search for the assigned Query. If you want to calculate the count of tags which are present in your search result or you want to know how many templates for a particular page are there etc, you may go with Facets based search.
p.guesstotal : The purpose of the p.guessTotal parameter is to return the appropriate number of results that can be shown by combining the minimum viable p.offset and p.limit values. The advantage of using this parameter is improved performance with large result sets. This avoids calculating the full total (e.g calling result.getSize()) and reading the entire result set.
p.offset : defines start of index means from which index you want to fetch records from query result.
p.limit : defines page size. In simple words how many records you want to fetch. Each query result will display results from p.offset to p.offset + p.limit.
Query Builder JAVA API
Now that we've gone through the number of standard predicates available with us, let's use these queries in our java code and get the required result via Java API.
We can use AEM queries in three ways in java:
-
Using HTTP request
Session session = request.getResourceResolver().adaptTo(Session.class); PredicateGroup root = PredicateGroup.create(request.getParameterMap()); Query query = queryBuilder.createQuery(root, session); -
Using Predicates
PredicateGroup group = new PredicateGroup(); group.add(new Predicate("mypath", "path").set("path", "/content/mysite")); group.add(new Predicate("mytype", "type").set("type", "cq:Page")); Query query = queryBuilder.createQuery(group, session); -
Using Hash Map
Map
When we get the query, we can simply get the search results in the form of hits and we can iterate over the list of results i.e., hits and use that result in our java code.
//Get search results
SearchResult result = query.getResult();
List resultList = result.getHits();
//Iterate query results
for (Hit hit : resultList ) {
// Write your logic here
}
Hope you got the concept of query builder and how to write queries and use those queries in our java code as well. We'll go through some sample set of examples of creating queries in the next blog.
Thanks for reading! 😄


